


Инкрементальные модели в dbt позволяют обрабатывать только новые или обновленные строки в таблице, что значительно улучшает производительность, так как вам не нужно пересоздавать всю таблицу с нуля.


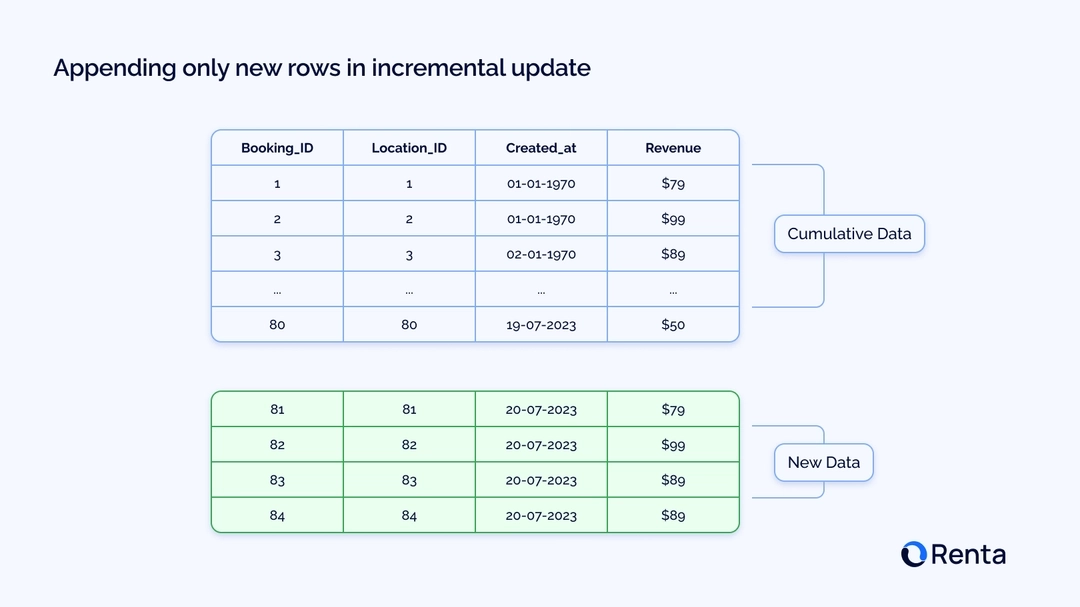
Этот подход ускоряет трансформации и снижает вычислительные затраты. Однако настройка этих моделей может быть сложной для новичков.
В этом руково�дстве мы разберем:
Содержание
- Что такое инкрементальные модели?
- Настройка инкрементальной модели в dbt
- Создание dbt-модели с настройкой инкрементального обновления
- Как работает is_incremental()
- Запуск dbt-модели
- Обработка изменений схемы с помощью инкрементальных стратегий
- Merge с unique_key
- Merge с обновлением столбцов (update columns)
- Заключение
Давайте начнем.
Что такое инкрементальные модели?
В отличие от традиционного метода материализации таблиц, который пересоздает всю таблицу при каждом запуске задания в dbt, инкрементальные модели обрабатывают только новые или обновленные строки в вашем наборе данных.

Этот подход минимизирует объем данных, которые необходимо трансформировать, сокращая время выполнения и снижая стоимость выполнения запросов.
Как это работает?
Инкрементальные модели фильтруют строки, которые были добавлены или обновлены, на основе определенного столбца. Обычно это временная метка (timestamp) или уникальный ключ (например, номер заказа в целочисленном формате). В этом контексте я буду называть этот ключ контрольной точкой (checkpoint).
Задание dbt сравнивает значение контрольной точки в этом столбце с максимальным значением, которое уже присутствует в целевой таблице.
Например, предположим, что вы работаете с таблицей событий поведения пользователей на сайте. В этом случае инкрементальная модель будет об�рабатывать только те новые события, дата и время которых больше, чем самая поздняя дата в вашей существующей модели данных.
Настройка инкрементальной модели в dbt
Первым шагом при работе с инкрементальными моделями в dbt является установка конфигурации модели.
Укажите тип материализации
В начале модели вы должны указать тип материализации как incremental. Это делается с помощью блока config():
{{ config(
materialized='incremental'
) }}Это сообщает dbt, что модель должна обновляться инкрементально, то есть добавлять только новые или обновленные строки во время каждого запуска, а не перезаписывать всю таблицу целиком.
Создание dbt-модели с настройкой инкрементального обновления
Далее следует основной SQL-запрос, который будет использоваться для построения модели. Вот пример запроса из реального проекта:
{{ config(
materialized='incremental'
) }}
SELECT *, CURRENT_TIMESTAMP() AS batch_timestamp -- фиксация времени загрузки
FROM {{ source('tracking_v2', 'renta_events') }}
WHERE date >= '2025-03-01' -- базовый фильтр по дате
{% if is_incremental() %}
AND dateTime > (SELECT MAX(dateTime) FROM {{ this }}) -- инкрементальное условие
{% endif %}Как работает is_incremental()
Блок is_incremental() — это встроенная макро-функция dbt. Она возвращает true, если:
- Таблица уже существует в базе данных.
- Модель запущена без флага
--full-refresh. - Тип материализации установлен как
incremental.
Если все эти условия соблюдены, dbt применяет к запросу дополнительное условие:
AND dateTime > (SELECT MAX(dateTime) FROM {{ this }})Это условие сравнивает столбец dateTime исходной таблицы с максимальным значением dateTime в целевой таблице.
Запуск dbt-модели
Запустите dbt-модель с помощью команды dbt run:
dbt run --select my_incremental_modelСначала модель проверит, существует ли целевая таблица и запущен ли dbt в режиме полного обновления.
Если таблица не существует, dbt обработает это как полное создание таблицы. Если таблица существует, dbt просто добавит новые данные.
Что происходит при первом запуске?
Создается новая таблица. Данные полностью переносятся из исходной таблицы во вновь созданную модель.
При последующих запусках dbt будет добавлять только новые строки. Отслеживать новые записи удобнее всего с помощью добавленного поля batch_timestamp, которое помогает следить за данными, обработанными в каждом запуске. batch_timestamp — это уникальная временная метка для каждого вставленного пакета. Это позволяет отслеживать, какие записи были добавлены во время каждого запуска dbt-задания, что полезно для отладки модели.
Пересборка модели с нуля
Иногда вам может потребоваться полностью обновить таблицу, например, когда нужно добавить новые столбцы (хотя для этого случая есть более подходящая операция).
Чтобы выполнить полное обновление, запустите следующую команду:
dbt run --full-refresh --select my_incremental_modelЧто делает эта команда:
- Удаляет текущую версию таблицы.
- Создает таблицу заново.
- Загружает все доступные данные из исходной таблицы (без инкрементального фильтра).
Эта команда удалит таблицу, сотрет все существующие данные, создаст новую таблицу с новой схемой и перезагрузит данные с нуля.
Обработка изменений схемы с помощью инкрементальных стратегий
Если схема данных меняется, dbt предоставляет несколько вариантов того, как это следует обрабатывать, через конфигурацию on_schema_change:
| Стратегия | Описание |
|---|---|
| ignore | Поведение по умолчанию. Изменения схемы игнорируются. |
| append_new_columns | Добавляет новые столбцы в таблицу, но не обновляет их значениями для существующих строк. |
| fail | Останавливает выполнение, если схема не синхронизирована с моделью. |
| sync_all_columns | Добавляет новые столбцы и удаляет устаревшие столбцы для поддержания синхронизации. |
Это поведение зависит от используемого хранилища данных (подробности см. в документации dbt).
Ниже приведен пример настройки конфигурации on_schema_change в вашей dbt-модели:
{{ config(
materialized='incremental',
unique_key='eventId',
incremental_strategy='merge',
on_schema_change='append_new_columns'
) }}Что здесь происходит?
Давайте разберем конфигурацию подробнее:
| Параметр | Значение | Описание |
|---|---|---|
| materialized | incremental | Модель будет обновляться инкрементально, добавляя только новые строки. |
| unique_key | eventId | dbt будет использовать eventId в качестве уникального ключа таблицы для обнаружения и слияния дублирующихся строк. |
| incremental_strategy | merge | Гарантирует, что новые строки добавляются, а существующие строки с совпадающими ключами обновляются. |
| on_schema_change | append_new_columns | Если в источнике появятся новые столбцы (например, user_agent, payment_method), они будут авто�матически добавлены в модель без ошибок. |
Вы должны помнить, что новые столбцы, добавленные через on_schema_change, не обновят существующие строки.
Если вам нужно обновить эти строки, необходимо выполнить перезапуск модели с флагом --full-refresh.
Давайте разберем несколько примеров стратегий слияния (merge). Эти примеры продемонстрируют различные конфигурации моделей, подчеркивая лучшие практики оптимизации ваших инкрементальных трансформаций данных в dbt.
Merge с unique_key
Используя стратегию слияния, рассмотрим модель, в которой новые или обновленные строки заменяют старые на основе order_id.
{{ config(
materialized = 'incremental',
incremental_strategy = 'merge',
unique_key = 'order_id'
) }}
{% if not is_incremental() %}
select cast(1 as int) as order_id, 'Alice' as customer
union all
select cast(2 as int) as order_id, 'Bob' as customer
{% else %}
select cast(2 as int) as order_id, 'Charlie' as customer
union all
select cast(3 as int) as order_id, 'Diana' as customer
{% endif %}Результат:
-- После 1-го запуска
> select * from orders_merge order by order_id
|+-----------+----------+
|| order_id | customer |
|+-----------+----------+
|| 1 | Alice |
|| 2 | Bob |
|+-----------+----------+
-- После 2-го запуска
> select * from orders_merge order by order_id
|+-----------+----------+
|| order_id | customer |
|+-----------+----------+
|| 1 | Alice |
|| 2 | Charlie |
|| 3 | Diana |
|+-----------+----------+При использовании стратегии слияния вместе с уникальным ключом строка с order_id = 2 была обновлена (Bob → Charlie), и был вставлен новый заказ с order_id = 3.
Merge с обновлением столбцов (update columns)
В некоторых случаях необходимо обновить только определенные поля, оставив остальные без изменений. Например, мы можем захотеть обновить сумму (amount), не изменяя уже сохраненную дату заказа (order_date).
{{ config(
materialized = 'incremental',
incremental_strategy = 'merge',
unique_key = 'order_id',
merge_update_columns = ['amount']
) }}
{% if not is_incremental() %}
select cast(1 as int) as order_id, 50.00 as amount, '2024-01-01' as order_date
union all
select cast(2 as int) as order_id, 70.00 as amount, '2024-01-01' as order_date
{% else %}
select cast(2 as int) as order_id, 75.00 as amount, '2024-01-05' as order_date
union all
select cast(3 as int) as order_id, 60.00 as amount, '2024-01-03' as order_date
{% endif %}Результат:
-- После 1-го запуска
> select * from orders_merge_update_columns order by order_id
|+-----------+--------+-------------+
|| order_id | amount | order_date |
|+-----------+--------+-------------+
|| 1 | 50.00 | 2024-01-01 |
|| 2 | 70.00 | 2024-01-01 |
|+-----------+--------+-------------+
-- После 2-го запуска
-- Для order_id = 2 была обновлена только сумма. Order_date остался без изменений.
> select * from orders_merge_update_columns order by order_id
|+-----------+--------+-------------+
|| order_id | amount | order_date |
|+-----------+--------+-------------+
|| 1 | 50.00 | 2024-01-01 |
|| 2 | 75.00 | 2024-01-01 |
|| 3 | 60.00 | 2024-01-03 |
|+-----------+--------+-------------+Конфигурация merge_update_columns позволяет точно контролировать, какие поля обновляются. В нашем примере мы сохранили исходную order_date и обновили только значения суммы.
Заключение
Надеюсь, этот материал послужит отличной отправной точкой для изучения инкрементальных обновлений в dbt. Также я рекомендую ознакомиться с ресурсами ниже, которые охватывают различные стратегии настройки инкрементальных обновлений:
- How to Build Incremental Models от Kahan Data Solutions (я считаю, что это лучшее руководство, которое можно найти на YouTube).
Если у вас есть вопросы, не стесняйтесь связаться со мной в LinkedIn. Если вы используете dbt, рассмотрите возможность интеграции Renta ELT с dbt Cloud, что расширяет контроль над загрузкой и управлением вашими конвейерами данных.





