

Современный стек данных — это набор инструментов для сбо�ра и обработки всех данных, необходимых для развития вашего продукта в 2026 году.
Как выглядит современный стек аналитики данных?
Проще говоря, это интегрированная модульная система технологий для анализа эффективности вашего бизнеса. Уровни стека состоят из множества инструментов, каждый из которых выполняет одно простое действие, такое как хранение данных, объединение и преобразование данных, а также их визуализация. Благодаря этому система легко настраивается и адаптируется.



Например, вы можете заменить инструмент для передачи данных на более эффективный без необходимости перенастраивать все остальные уровни. По сути, современная система аналитики данных должна состоять из трех этапов:
Сбор, консолидация и хранение данных. Чтобы иметь возможность систематизировать и в дальнейшем анализировать данные, сначала необходимо собрать все необработанные данные, которые вы можете получить, и сохранить их в одном месте — в хранилище данных (Data Warehouse).
Преобразование данных. Необработанные данные часто содержат избыточную информацию, которая не может быть значимой или полезной для отделов маркетинга или продукта. Все собранные данные должны быть очищены, преобразованы и приведены в нужный вид для дальнейшего использования.
Отчетность и анализ. Данные приносят больше пользы бизнесу, когда они хорошо представлены и понятны всем членам команды.
Давайте подробнее рассмотрим каждый этап, чтобы лучше понять современную систему аналитики.
Сбор данных
Скорее всего, ваша компания собирает информацию из нескольких источников данных, например, из Google Analytics, показателей эффективности рекламы и расходов, маркетинговых инструментов и CRM-приложений. Чтобы увидеть общую картину, вам необходимо централизовать все эти данные в хранилище.
Хранилище — это центральное звено вашего аналитического стека. Вы собираете в него необработанные данные из всех источников, чтобы позже преобразовать информацию и использовать ее в отчетах.


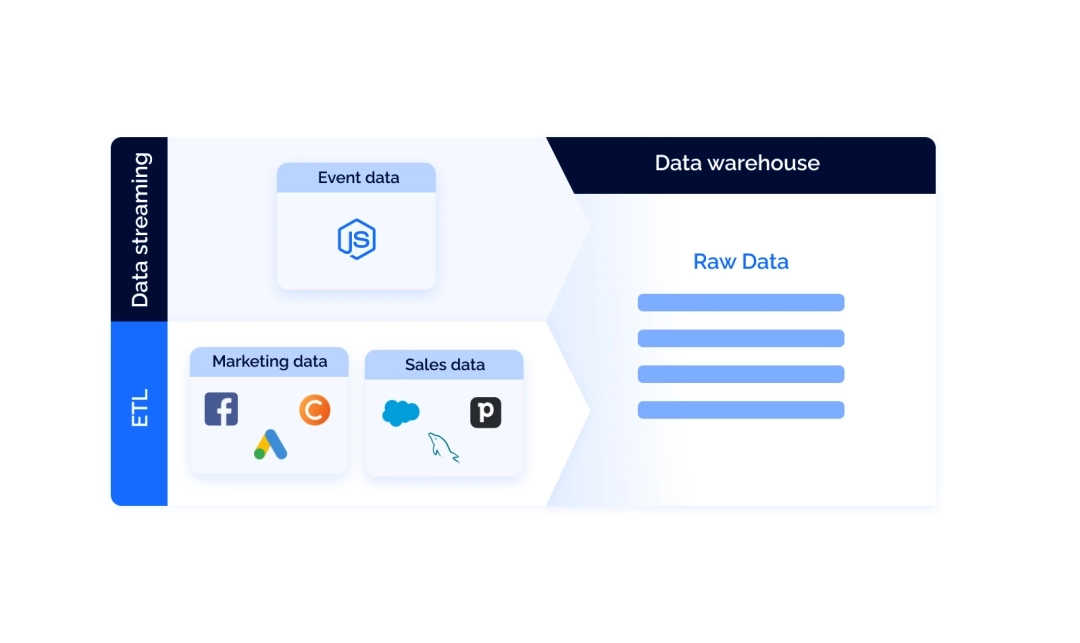
Этап сбора данных в продуктовой и маркетинговой аналитике состоит из трех важных компонентов:
- Хранилище данных (Data Warehouse)
- Потоки данных о поведении пользователей
- ETL-конвейеры
Хранилище данных
Существует множество облачных решений для хранения данных, например, Snowflake ил�и Google BigQuery. При выборе хранилища следует тщательно проанализировать, как вы используете и обрабатываете данные, так как у каждого решения есть свои особенности и нюансы ценообразования.
BigQuery, например, автоматически корректирует стоимость в зависимости от потребления данных. Это означает, что вам не нужно беспокоиться о превышении лимитов тарифного плана — платформа будет выставлять счета в соответствии с вашим потреблением.
Snowflake, с другой стороны, дает вам больше контроля над архитектурой хранилища данных. Это обеспечивает более прозрачную и предсказуемую систему ценообразования, но также накладывает некоторые ограничения на хранение данных и производительность запросов.
Следующим шагом после настройки хранилища является создание конвейеров данных (Data Pipelines). Конвейер данных — это, по сути, процесс перемещения данных из одного места (источника) в другое (в нашем случае — в хранилище). Обычно существуют два типа данных, для которых требуются выделенные конвейеры: данные о поведении пользователей и сторонние данные.
Потоковая передача данных о поведении пользователей в реальном времени
Потоки в реальном времени собирают данные о поведении пользователей из вашего приложения или веб-сайта. Инструменты, такие как Renta Javascript SDK, отслеживают всю активность пользователей на вашем сайте или в приложении и отправляют ее в ваше хранилище. Важно, что подобные инструменты поддерживают серверную интеграцию и обеспечивают сбор данных как собственных данных (first-party data), обходя ограничения сторонних файлов cookie (third-party cookies). Это позволяет повысить качество данных.
Инструменты потоковой передачи данных в реальном времени являются хорошей альтернативой Google Analytics 360. Они гарантируют соблюдение требований GDPR и сохранение качества данных при использовании технологий предотвращения интеллектуального отслеживания (ITP), оставаясь при этом гораздо более доступными.
ETL/ELT конвейеры
Эти конвейеры передают сторонние данные из внешних сервисов, которые вы используете в работе. Сторонними данными могут быть, например, подробности о ваших сделках из Salesforce или расходы на маркетинг из Facebook Ads. Для создания конвейера для такого типа данных лучше всего использовать инструменты ETL.
ETL расшифровывается как Extract (Извлечение), Transform (Преобразование) и Load (Загрузка). Как следует из названия, ETL-коннекторы работают в три этапа: собирают данные из различных источников API, затем обрабатывают их и, наконец, отправляют в хранилище.
Прелесть инструментов ETL в том, что они создают полностью автоматизированный процесс сбора данных, и вам не нужно прилагать к этому много усилий.
Например, Marketing ETL от Renta позволит вам настроить процесс для всех ваших источников за 4 простых шага. Как только вы настроите потоки как для внутренних, так и для внешних данных вашего бизнеса, в вашем хранилище будет вся информация, необходимая для 360-градусного обзора потребителей.
Преобразование данных
Необработанные данные чаще всего поступают в виде, не подходящем для бизнес-отчетности, именно поэтому этот этап необходим. Начальное преобразование выполняется во время сбора данных (помните, что означает буква T в ETL?). Однако этого недостаточно для надлежащего представления или анализа.
Дальнейшая обработка этих данных включает в себя категоризацию, унификацию, стандартизацию, адаптацию к потребностям бизнеса, объединение и многое другое. По сути, преобразование данных ведет к созданию витрин данных (Data Marts) — предметно-ориентированных кластеров данных.

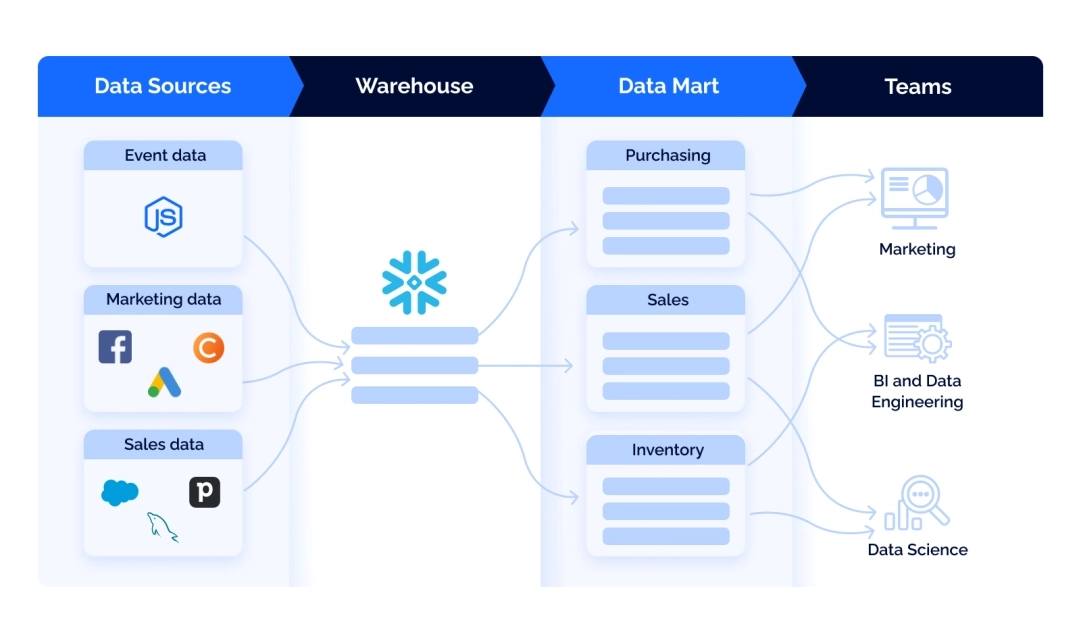
Витрины данных разделяют всю информацию в вашем хранилище на более мелкие блоки, предназначенные для конкретных бизнес-подразделений — например, продаж, маркетинга или финансов.
На данный момент наиболее эффективным инструментом для преобразования данных, а также создания и управления витринами данных является dbt.
dbt (data build tool) — это фреймворк с открытым исходным кодом, который позволяет аналитикам и инженерам преобразовывать данные в своих хранилищах. Все, что делает dbt — это компилирует данные в SQL-запросы, а затем запускает их в вашей базе данных. Это звучит просто, но это действительно меняет правила игры.


В то время как ETL-конвейеры выполняют первоначальное преобразование данных, dbt обрабатывает данные, которые уже находятся в хранилище, и создает витрины данных.
dbt помогает распределить SQL-запросы по папкам вашего проекта так, чтобы их было легко найти и выполнить любому члену команды.
С помощью dbt вы можете применять логику программирования к аналитике. Он позволяет создавать многократно используемый модульный код с помощью Jinja для создания моделей, на которые можно ссыл�аться позже вместо того, чтобы каждый раз вручную писать SQL-запросы. Это позволяет компилировать запросы в зависимости от используемого вами хранилища данных — если вы смените решение для хранения, вам не придется переписывать запросы.
Более того, dbt позволяет документировать данные, отслеживать ошибки, синхронизироваться с GitHub, проводить тестирование и многое другое.
Отчетность
Заключительным этапом обработки данных является их визуализация в виде понятных графиков и отчетов. На этом этапе вы используете различные инструменты визуализации, такие как Looker или Power BI, для оперативной отчетности, регулярной отчетности и исследования данных.

Используя системы бизнес-аналитики (BI), вы можете составлять отчеты на основе данных из различных источников, задавать ключевые показатели и создавать визуализации — все это автоматизировано и регулярно обновляется. BI-системы подключаются к вашему хранилищу данных и готовят отчеты без каких-либо усилий с вашей стороны.
В заключение
Данные — это движущая сила любого современного бизнеса. Они могут дать вам представление о том, как ваши клиенты взаимодействуют с вашими продуктами и как вы можете сделать это взаимодействие лучше для конечного пользователя и более прибыльным для вас. Чтобы найти эти идеи, вам необходимо настроить мощный аналитический стек, который будет собирать и обрабатывать всю информацию за вас.
Современный аналитический стек должен отражать простой трехэтапный процесс: сбор-обработка-выполнение. Все эти этапы могут быть автоматизированы и оптимизированы — и как только все будет настроено, вы сможете приступить к интерпретации и использованию этих данных для развития вашего бизнеса.




