

Компании всё чаще используют данные о пользователях, чтобы принимать обоснованные решения, дорабатывать свои предложения и повышать качество обслуживание. Чтобы эффективно использовать данные, важно выбрать оптимальную систему хранения.
На рынке так много систем для хранения данных, что может быть трудно выбрать лучшую для вашего бизнеса. Чтобы избавить вас от мук выбора, мы сравнили три самых распространённых метода хранения данных: data warehouse, data lake и data lakehouse. Узнайте о них больше и подберите метод, который будет хранить ваши данные.
Содержание
- Data Warehouse, Data Lake, Data Lakehouse: краткое резюме
- Что такое хранилище данных
- Компоненты хранилищ данных
- Преимущества и недостатки хранилищ данных
- Что такое озеро данных
- Компоненты озера данных
- Преимущества и недостатки озёр данных
- Data lake и data warehouse: какое решение использовать
- Что такое data lakehouse
- Компоненты data lakehouse
- Преимущества и недостатки data lakehouse
- Data warehouse, Data Lake или Data Lakehouse: Обзор
- Ключевые выводы
Data Warehouse, Data Lake, Data Lakehouse: краткое резюме
Хранилище данных (data warehouse) хранит преобразованные и структурированные данные из разных источников: CRM- и транзакционных систем, сервисов для создания рекламы и т. д. Бизнес-аналитики, маркетологи, дата-инженеры могут получить к ним доступ с помощью инструментов BI, SQL-клиентов и других аналитических приложений.
Озеро данных (data lake) хранит полу- и неструктурированные данные, что позволяет загружать их в хранилище и использовать на усмотрение команды. Метод предполагает глубокую аналитику и машинное обучение. Кроме того, озеро данных стоит меньше базы данных, его проще настроить и масштабировать.
С другой стороны, озёра данных не организованы, так что нужно уметь с ними работать. В противном случае они быстро превратятся в «болота данных».
Дом озера данных (data lakehouse) — гибридное решение для хранения данных. Оно сочетает лучшие свойства хранилищ и озёр данных. Data lakehouse может хранить все виды данных и позволяет управлять метаданными.
Гибридное решение стоит меньше, чем data warehouse, и проще масштабируется.
Хранилища данных хорошо использовать в инструментах бизнес-аналитики, для составления отчётов и построения графиков. Озёра данных подходят в случаях, когда нужно проанализировать большой объём данных и настроить машинное обучение. Гибридное решение покрывает все варианты использования.
Прежде чем мы начнём сравнивать методы, напомним, какие типы данных можно хранить в data warehouse, data lake и data lakehouse:
Структурированные данные — это обработанная информация. Они могут включать имена, даты, геолокацию, номера телефонов и т. д.
Неструктурированные данные — информация без обработки и полноценного фреймворка. Могут включать видео, изображения, аудиофайлы.
Полуструктурированные данные — частично обработанная информация. Например, файлы CSV, JSON, XML.
Что такое хранилище данных
Хранилище данных — это решение, в котором хранятся структурированные данные из разных источников. Прежде чем попасть в хранилище, данные проходят первоначальную обработку. Маркетологи, аналитики, продуктовые менеджеры могут сразу использовать такие данные для работы: проверять, обобщать, анализировать, объединять, составлять отчёты.
Популярные поставщики data warehouse: Google BigQuery, Snowflake и Amazon Redshift.
Компоненты хранилищ данных
Хранилища данных содержат четыре основных компонента:


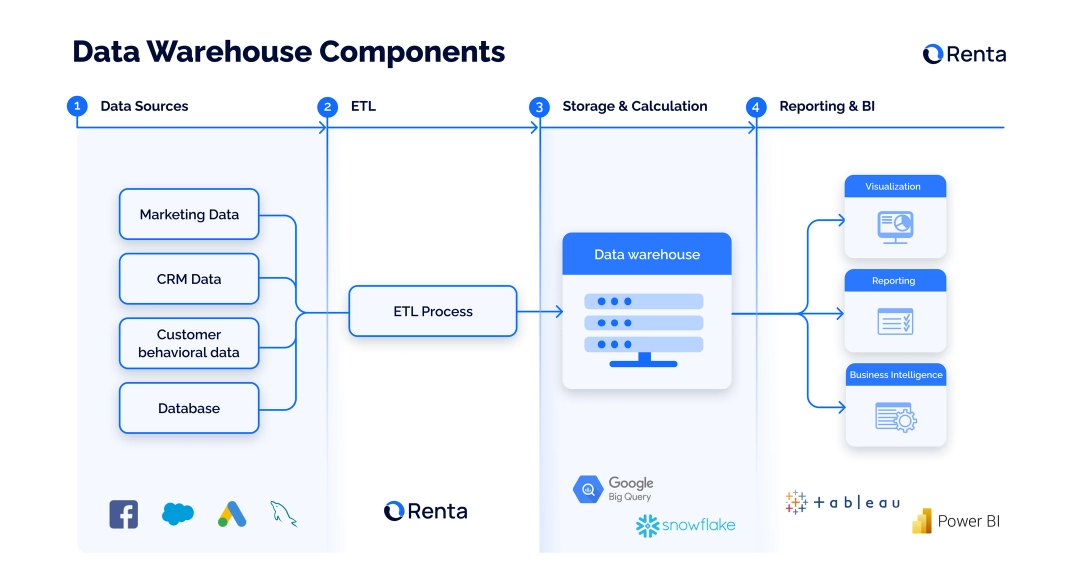
Инструменты интеграции данных (data integration tools) извлекают данные из разных источников, преобразуют их и загружают в единую базу. Такие конвейеры данных называются инструментами ETL.
Центральная база данных — пространство, где хранятся витрины данных. Это основа решений для хранилища данных.
Метаданные — информация о данных в хранилище. По сути, это схема таблиц в хранилище, которая описывает, какие данные хранятся в каждом их поле.
Инструменты доступа к данным включают ПО, которое позволяет командам обращаться к данным, собранным в data warehouse, — в центральной базе данных. К таким инструментам относятся инструменты запросов и разработки приложений, BI-решения и инструменты аналитической обработки.
Преимущества и недос�татки хранилищ данных
Преимущества:
- Гарантируют стандартизацию и согласованность данных. В хранилище данных можно загружать данные из приложений и инструментов, которые используют команды внутри компании. Все эти данные хранятся в центральной базе данных.
- Делают данные доступными. Данные уже преобразованы — команды могут в любой момент получить их и использовать в работе.
Недостатки:
- Не учитывают часть данных. Необработанные данные, которые не получается аккуратно вписать в хранилище данных, остаются за его пределами.
- Стоят дорого.
Data warehouse— дорогой инструмент, особенно при обработке больших объемов данных.
Что такое озеро данных
Озеро данных — централизованное хранилище, в котором хранятся структурированные, полу- и неструктурированные исходные данные. Озёра данных могут получать информацию в режиме реального времени. В data lake можно загружать данные без информационных потерь.
Когда вам понадобятся данные, вы сможете извлечь их из хранилища и обработать для конкретного дела — проверки, классификации, обобщения и т. п.
Озеро данных — это масштабируемое, гибкое и выгодное по стоимости решение для хранения информации.
Компоненты озера данных
Приём данных в озере обычно следует паттерну ISASA:

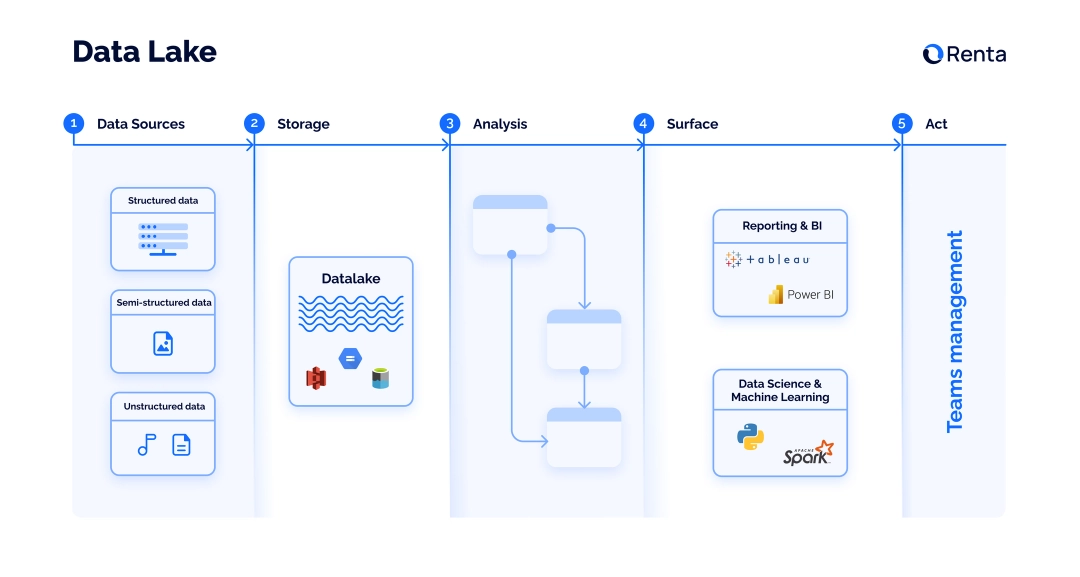
Приём (Ingest) подразумевает передачу данных через API или в пакетном режиме. Чтобы обработать данные, команды используют ETL-решения. Надёжный и простой ETL-инструмент, который позволяет создавать конвейеры за пару минут, — Renta Marketing ELT. В инструменте есть интеграции с популярными решениями для хранения данных.
Хранение (Store) подразумевает сбор данных в централизованном хранилище. Для хранения данных обычно используют сервисы Amazon S3, Google Cloud Storage и Azure Data Lake Storage Gen 2.
Анализ (Analyze) предполагает обработку данных.
Обработка (Surface) подразумевает форматирование информации в виде диаграмм, графиков и эскизов с использованием инструментов BI.
Действие (Act) предполагает доработку бизнес-решений и управление командой в соответствии с идеями, полученными в ходе предыдущих двух шагов.
Преимущества и недостатки озёр данных
Преимущества:
- Обеспечивают гибкость данных. Озёра данных позволяют хранить информацию в любом формате и на любом носителе информации.
- Дают больше возможностей для аналитики. Так как данные хранятся в необработанном формате, вы сможете проводить более глубокую аналитику и использовать разные алгоритмы машинного обучения.
- Имеют адекватную стоимость. Данные хранятся на недорогом оборудовании, так что стоимость гигабайта обойдётся дешевле, че�м в хранилище данных.
Недостатки:
- Требуют сильного управления. Озеро данных хранит неструктурированные данные, так что оно может легко превратиться в болото. Команде нужен специалист, способный обрабатывать дублированные и низкокачественные данные.
- Не гарантируют безопасности. В озеро данных сложно внедрить политику безопасности. По этой причине невозможно гарантировать, что данные останутся конфиденциальными.
Популярные облачные решения для хранения данных: Amazon S3, Google Cloud Storage, Azure Data Lake Storage Gen 2. Решения, подобные Amazon Web Services (AWS), имеют встроенные инструменты, такие как AWS Lake Formation, которые позволяют повысить безопасность озера данных, создать слой метаданных и управлять доступом к информации внутри команды.
Отметим, что формирование озера AWS охватывает большинство этапов схемы ISASA.
Data lake и data warehouse: какое решение использовать
Итак, чем озеро данных отличается от хранилища данных и какое решение использовать?
Архитектура хранилища данных позволяет с�обирать и хранить структурированные данные, которые можно использовать для отчётов, информационных панелей и т. д. Структура данных и система в data warehouse определены заранее, что обеспечивает высокое качество данных и простой доступ к ним. Хранилище данных — оптимальное решение для маркетинговых, продуктовых, аналитических команд.
Архитектура озера данных позволяет хранить все виды данных. Данные не нужно предварительно обрабатывать — можно просто сбросить их в озеро и обработать позже. Такое решение подойдёт, если вы планируете проводить машинное обучение, анализировать большой массив данных. Но учтите, что отсутствие метаданных и большой объём неструктурированных данных могут превратить озеро в «болото данных», где будет трудно найти полезную информацию.
Что такое data lakehouse
Data lakehouse — это современное гибридное решение. Новая открытая архитектура использует лучшие элементы хранилища данных и сочетает их с масштабируемостью, гибкостью и низкой стоимостью озера данных.
Хранилище озера данных хранит все виды данных в одном месте. Это позволяет пр�още управлять данными, повысить масштабируемость и снизить траты. Кроме того, решение не имеет ограничений, типичных для обоих форматов хранения.
Data lakehouse помогает компаниям раскрыть потенциал своих данных. Решение даёт постоянный доступ к новой информации и к данным, добавленным в систему ранее.
Компоненты data lakehouse
Шаблон data lakehouse состоит из пяти слоёв:

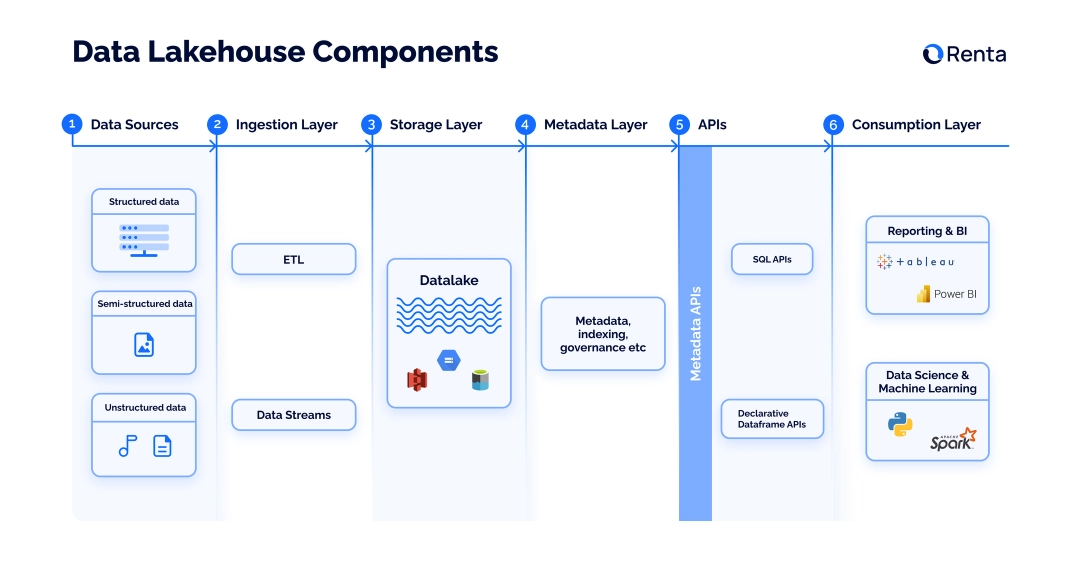
Приём (Ingestion layer). Данные поступают из разных источников и передаются в базу данных.
Хранение (Storage layer). Это объект облачного хранилища, аналогичный хранилищу озера данных. Объект вмещает все типы данных.
Метаданные (Metadata layer). Представлен в формате единого каталога, который содержит метаданные обо всех объектах в хранилище. Слой обеспечивает организацию озера данных, простое управление данными, индексирование, принудительное применение схемы и транзакции ACID.
API (API layer). Позволяет получать доступ к данным и извлекать их из хранилища, быстрее решать свои задачи и получать продвинутую аналитику. API также помогают определить, какие элементы данных нужны для конкретного приложения и как их получить. Кроме того, библиотеки ML, такие как TensorFlow и Spark, могут напрямую запрашивать метаданные.
Использование (Consumption layer). Этот слой включает в себя приложения и бизнес-инструменты, которые используют данные для создания отчётов, обработки данных (BI) и искусственного интеллекта.
Преимущества и недостатки data lakehouse
Преимущества:
- Поддерживают высокую рабочую нагрузку. Как и озеро данных, решение может хранить необработанные данные, что позволяет проводить расширенную аналитику и машинное обучение.
- Управляют данными. Вычислительный уровень обеспечивает функции организации и управления, характерные для DWH. Этот компонент не даёт хранилищу превратиться в болото данных.
- Гарантируют безопасность. Архитектура data lakehouse такова, что внедрить механизмы защиты данных и управлять ими легко.
- Имеют адекватную стоимость. Используются недорогие объектные хранилища, а данные хранятся в открытых форматах, таких как
JSONилиParquet.
Недостатки:
- «Сырая» технология. Data lakehouse — относительно новый подход, и потребуется время, чтобы технология стала такой же зрелой и изученной, как классические решения.
Data warehouse, Data Lake или Data Lakehouse: Обзор
Нет однозначного ответа, какая технология лучше. Все зависит от потребностей вашего бизнеса и возможностей команд.
| Параметр | Data warehouse | Data lake | Data lakehouse |
|---|---|---|---|
| Тип данных | Структур�ированные | Любые (сырые) | Любые (структур. и сырые) |
| Качество данных | Высокое, очищенные данные | Низкое (сырые данные) | Высокое, поддержка схем |
| Обработка | ETL (Extract, Load, Transform) | ELT (Extract, Transform, Load) | И ETL, и ELT |
| Стоимость | Высокая (хранение и процессинг) | Низкая (объектное хранение) | Низкая (объектное хранение) |
| ACID-транзакции | Да | Нет | Да |
| Аналитика | BI, регулярная отчетность | Data Science, ML, Big Data | BI, ML, продвинутая аналитика |
| Пользователи | Аналитики, бизнес-пользователи | Data Scientist, Data Engineer | Все типы пользователей |
Ключевые выводы
Хранилище данных — оптимальное решение для маркетинговых команд, которые хотят использовать структурированные данные, готовые к использованию в отчётах или инструментах BI.
Data lakehouse, построенные на таких платформах, как Databricks, — хороший выбор для обработки больших объёмов структурированных данных с возможностью расширенной аналитики.
Озеро данных подойдёт командам, которые умеют обрабатывать неструктурированные данные. Неумелое обращение с такими данными превратит озеро данных в болото.
Если вы сейчас создаёте собственное решение для анализа данных, обратите внимание на продукты Renta: Javascript SDK и Marketing ETL. С помощью первого инструмента вы легко создадите надёжный конвейер first-party данных, а с помощью второго — интегрируете информацию в популярные хранилище данных.


