
Современный дата-стек — это набор инструментов, которые помогают собирать и обрабатывать данные, нужные для развития продукта.
Как выглядит современный дата-стек для аналитики?
Говоря простыми словами, это интегрируемая модульная система технологий, позволяющая отслеживать эффективность бизнеса. Слои стека состоят из инструментов, каждый из которых выполняет одно действие, например, хранит, объединяет, преобразовывает или визуализирует данные. Систему можно настроить под себя и задачи бизнеса.


К примеру, вы можете изменить ваш инструмент конвейера данных на более эффективный, и тогда вам не придётся перенастраивать остальные слои. По сути, современная система анализа данных должна состоять из трех этапов:
Сбор, консолидация и хранение данных
Чтобы систематизировать и проанализировать данные, вам нужно собрать все необработанные данные, которые вы можете получить, и использовать их в хранилище данных.Преобразование данных
Необработанные данные часто содержат информацию, которая может оказаться незначимой или лишней для маркетинговой или продуктовой команды. Всю собранную информацию нужно очистить, преобразовать и сохранить так, чтобы её можно было использовать позже.Отчётность и анализ
Данные полезны для бизнеса, когда они качественно преобразованы и понятны всем членам команды.
Рассмотрим все слои стека, чтобы лучше понять современную систему аналитики.
Сбор данных
Скорее всего, ваша компания собирает информацию из нескольких источников данных: Яндекс.Метрики и Google Analytics, показателей эффективности рекламы и расходов, маркетинговых инструментов и CRM-системы. Чтобы увидеть общую картину, нужно собрать все эти данные в хранилище данных.

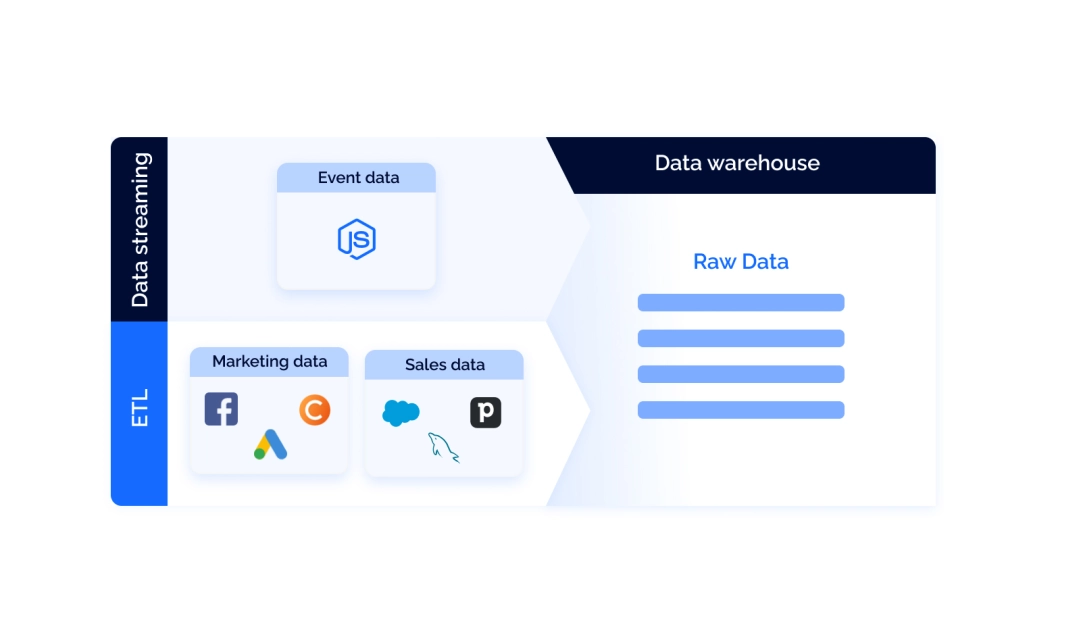
Сбор данных в продуктовой и маркетинговой аналитике состоит из трёх компонентов:
Хранилище данных
Данные о поведении пользователей
Конвейеры ETL
Хранилище данных
Есть разные решения для хранения данных, например, Snowflake или Google BigQuery. Выбирая облачное хранилище, проанализируйте, как вы планируете обрабатывать и использовать данные, потому что сервисы отличаются по стоимости и функционалу.
Так, BigQuery меняет стоимость тарифного плана в зависимости от того, сколько данных вы используете. Вам не придётся переживать, что вы превысили ограничения по вашему плану и будете вынуждены заплатить больше. А Snowflake позволяет создать прозрачную и прогнозируемую систему ценообразования, но при этом ограничивает производительность запросов и хранение данных.
Когда вы настроите хранилище, вам предстоит выстроить конвейер данных. По сути, это перемещение данных из одного места (источника) в другое (в вашем случае — в хранилище). Как правило, рассматривают два типа данных, которым нужны выделенные конвейеры: данные о поведении пользователей и данные третьих сторон (это данные, которые собирают компании и сайты, не имеющие прямого взаимодействия с потребителями).
Данные о поведении пользователей
Так называемые потоки поведения пользователей в реальном времени собирают данные о том, как ведут себя пользователи вашего сайта или приложения. Инструменты вроде Renta Javascript SDK отслеживают активность потребителей и отправляют её в ваше хранил�ище данных. Отметим, что такие сервисы поддерживают интеграции на стороне сервера и собирают данные от первого лица, минуя ограничения сторонних файлов cookie. Результат — высокое качество данных.
Такие инструменты, как Renta Javascript SDK, — хорошая альтернатива Google Analytics 360. Используя их, вы не нарушите постановлений Общего регламента по защите данных (General Data Protection Regulation, GDPR) и сохраните качество ваших данных.
Конвейеры ETL/ELT
Эти конвейеры передают сторонние данные из внешних сервисов, которыми вы пользуетесь. Под сторонними данными понимаются, к примеру, сведения о ваших маркетинговых расходах на рекламу в Facebook или о сделках из Salesforce. Построить конвейер для данных такого рода, мы рекомендуем использовать инструменты ETL.
ETL расшифровывается как Extract, Transform и Load. Инструменты ETL работают в три этапа: собирают данные из разных источников API, обрабатывают их и отправляют в хранилище. Их огромное преимущество заключаются в том, что они автоматизируют сбор данных.
Например, с помощью сервиса Renta’s Marketing ETL вы сможете всего за четыре шага настроить процессы для данных из всех ваших источников. Сделав это, вы получите в хранилище всю информацию, которая только может понадобиться для анализа потребителей вашего продукта.
Преобразование данных
Как правило, необработанные данные поступают в формате, который не подходит для бизнес-отчётности. Хотя первичное преобразование выполняется уже при сборе данных (та самая буква T в аббревиатуре ETL, помните?), этого недостаточно. Вот почему этот этап важен.
Дальнейшая обработка включает категоризацию, унификацию, стандартизацию данных, их адаптацию к потребностям бизнеса и т. п. По сути, это преобразование приводит к созданию витрины данных, предметно-ориентированных кластеров данных.
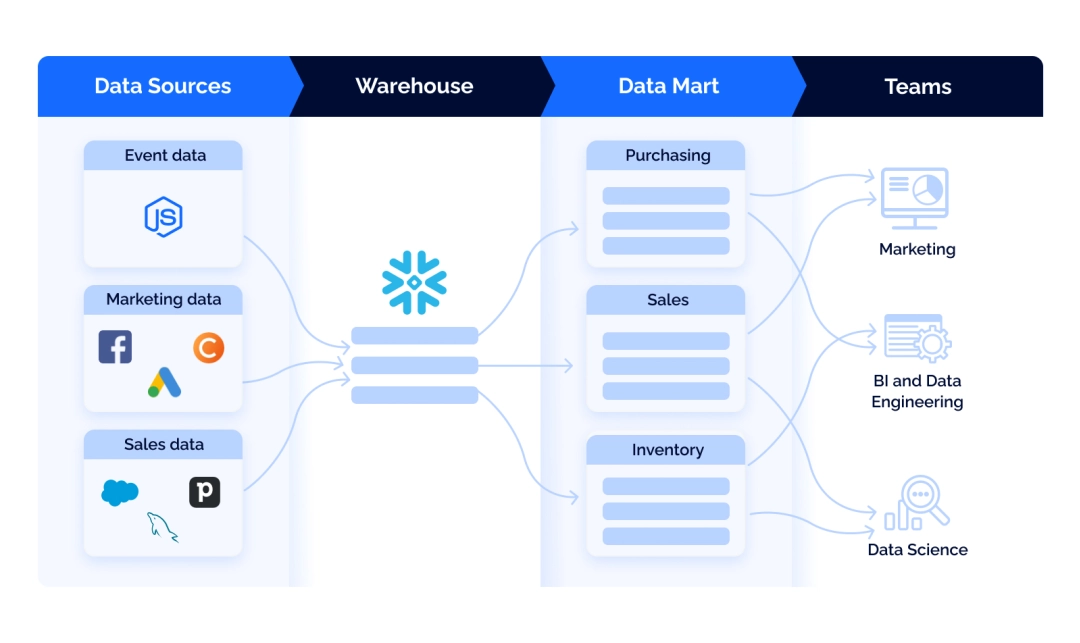
В витрине данных вся информация из вашего хранилища разделена на мелкие блоки, необходимые конкретным бизнес-подразделениям — отделу продаж, маркетинга или финансов.
Если вы ищете эффективный инструмент для преобразования данных, создания набора структурированных данных и управления ими, мы рекомендуем dbt (data build tool). Это платформа с открытым исходным кодом, которая позволяет аналитикам и инженерам преобразовывать данные в хранилищах. Она переводит данные в SQL-запросы и запускает их в базе данных.
Конвейеры ETL выполняют первичное преобразование данных, а dbt обрабатывает их при помощи SQL-запросов и создаёт витрины данных.
В итоге любой член вашей команды быстро найдёт данные в папке проекта и сможет выполнить запросы из неё.
С помощью dbt вы сможете отслеживать ошибки в наборе данных, использовать готовые инструменты тестирования качества и консистенцию данных, документировать данные, а также применять логику программирования к аналитике. Кроме того, вы сможете создать макросы и шаблоны обработки данных с использованием языков Jinja и Python. Вам не придётся каждый раз писать SQL-запросы вручную, даже если вы измените решение для хранения данных.
Отчётность и анализ
Заключительный этап обработки данных — это их визуализация. Здесь вы можете использовать инструменты, например, Looker или Power BI, чтобы создавать отчёты по заданным параметрам. BI-системы подключены к вашему хранилищу данных и обновляются автоматически.
 Заключение
Заключение
Данные — это движущая сила современного бизнеса. Изучив их, вы получите представление, как клиенты взаимодействуют с вашим продуктом и каким образом можно сделать это взаимодействие более комфортным. Задачу упростит мощный аналитический стек — он будет собирать и обрабатывать информацию для всех членов вашей команды.
Современный стек аналитики должен отражать трёхэтапный процесс: сбор, обработка и использование данных. Все эти шаги можно оптимизировать и автоматизировать. Используйте Marketing ETL, чтобы собирать данные из бизнес-приложений вроде Facebook Ads и amoCRM. А стриминг сырых данных Customer Behavioral Data поможет вам построить продуктовую и маркетинг-аналитику.


