

As businesses increasingly rely on data to make informed decisions, improve their offerings, and serve customers better, the amount of data they are collecting is on the rise. In order to make the most of this data, it is important to select the most optimal storage system.
With the variety of data storage systems out there, it can be difficult to determine which one is right for your company. Let's compare the three most common data storage architectures – a data warehouse, a data lake, and a data lakehouse – so you can choose the best option for your business.
Table of contents
- Data warehouse vs. data lake vs. data lakehouse — a quick summary
- What is a Data Warehouse?
- Data Warehouse pattern and components
- Pros and cons of data warehouse
- What is a Data Lake?
- Data Lake pattern and components
- Pros and cons of the Data Lake
- Data Lake vs. Data Warehouse
- What is a Data Lakehouse?
- Data Lakehouse pattern and components
- Pros and cons of data lakehouse
- Data warehouse vs. Data Lakehouse
- Data Warehouse vs. Data Lake vs. Data Lakehouse: Overview
- Key takeaways
Data warehouse vs. data lake vs. data lakehouse — a quick summary
Data warehouses store already transformed and structured data from multiple sources, such as transactional systems, CRMs, advertising managers, etc. Different teams within a company, including business analysts, data engineers and marketers, can access the data via BI tools, SQL clients and other analytics applications.
This structure allows for reliable high-quality data but also limits the analytics opportunities because of the predefined schema.
Data lakes store unstructured and semi-structured data, which allows quick dumping in the storage and then structuring it in accordance with the specific analytical purpose. This method enables deep analytics and machine learning. Additionally, it is more affordable and easily scalable than data warehouses.
On the other hand, because they are not organized, data lakes require strong management. Otherwise, they can very easily become data swamps.
Data lakehouse is a hybrid data storage solution that takes the best out of both data warehouses and data lakes. Lakehouses can keep structured, semi-structured, and unstructured data, but they also provide a strong metadata management system that allows for keeping the information organized.
Data lakehouses are easily scalable and less expensive than warehouses.
While data warehouses work well for business intelligence tools, reporting, and charting, data lakes are better for big data analysis and machine learning. Data lakehouses cover both use cases.
Before we move to the detailed analysis, let’s quickly go through the types of data you can store in your data storage:
Structured data is data that has been processed and normalized. Some examples include names, dates, geolocation, phone numbers, etc.
Unstructured data has not been processed. It doesn’t have a defined framework and is not organized. This can include videos, pictures, and audio files.
Semi-structured data implies having elements of both types of data mentioned above. Its framework is partly defined. For instance, unstructured data could be emails with structured information on the date, time, sender and recipient, but the body can comprise anything, including pictures, videos, and text files.
What is a Data Warehouse?
A data warehouse is a storage solution that keeps structured data from various data sources. The structured format of the data is the main focus here — before being uploaded to the warehouse, the raw data goes through an initial transformation. This way, it’s ready for further processing by different teams — marketing, product, analytics, etc.
The data in a warehouse is very organized and accessible — it is ready for validation, summarization, aggregation, analysis, reporting, or classification.
Popular cloud-based data warehouse providers are Google BigQuery, Snowflake, and Amazon Redshift.
Data Warehouse pattern and components
In order to provide well-structured ready-to-use data the data warehouse pattern is built from four core components:


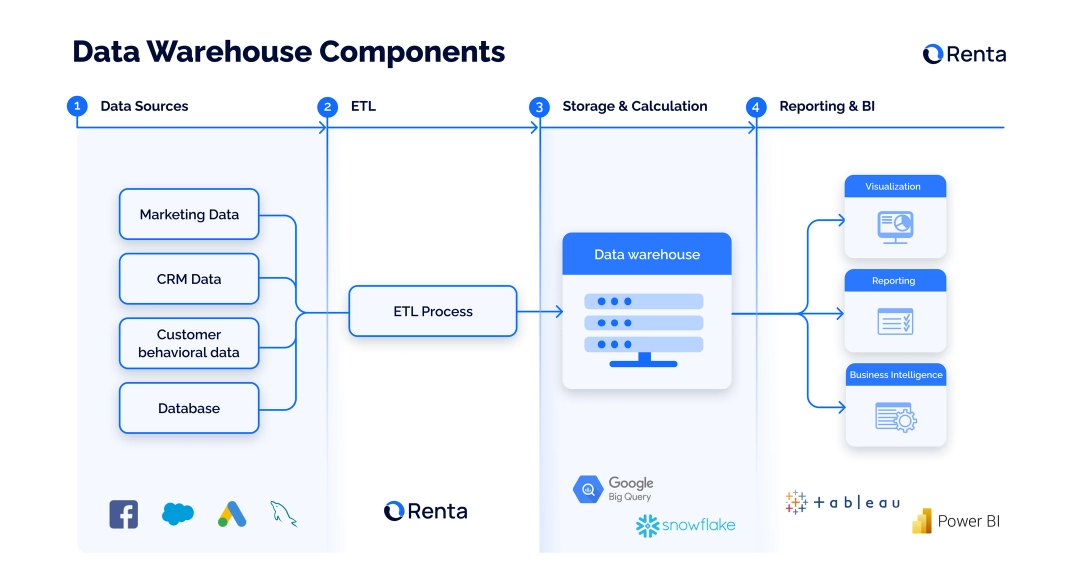
Data integration tools pull data from various sources, transform it so it fits the structure and then load it to the central database. These data pipelines are called ETL tools.
Central database is the space where all the data marts are stored. This is the backbone of any data warehouse solution.
Metadata is the information describing all the stored data at the warehouse. Basically, it’s a scheme of your tables in the warehouse that describes which type of data is stored in each field.
Data access tools include software that allows teams to obtain the data stored in the central database. These are query tools, application development tools, BI solutions, and online analytical processing tools.
Pros and cons of data warehouse
Data warehouses allow for highly organized storage and quick access to ready-to-use data. However, the solution has some drawbacks to it, too.
Pros:
- Ensures data standardization and consistency. A warehouse allows uploading data from different sources, meaning all the applications and tools used by different teams within a company. All that data is unified and stored in a centralized solution to provide a single source of data truth.
- Easy access to data. To start using the data for their purposes, the teams have to do little to no preparations as all the data is already transformed.
Cons:
- Part of data is lost. The part of raw data that can’t be fitted neatly in the warehouse organization structure gets sorted out.
- A pricey solution — especially with frequent data processing of huge datasets.
What is a Data Lake?
A data lake is a centralized repository solution that can store structured, unstructured, and semi-structured raw data. Data lakes can receive real-time data and store raw data that hasn’t been transformed — this allows quickly dumping all the information into the storage keeping every single bit of it.
When the data is needed, it can be pulled out from the storage and processed for a particular purpose — validation, summarization, classification, reporting, etc.
Data lakes provide a cost-effective, scalable and, more importantly, flexible storage solution. The issue with data lakes is that they are more difficult to keep organized, and it can be difficult to find the desired piece of data in it.
Data Lake pattern and components
A data lake implies the ISASA data implementation pattern, which includes five steps: Ingest, Store, Analyze, Surface, Act.

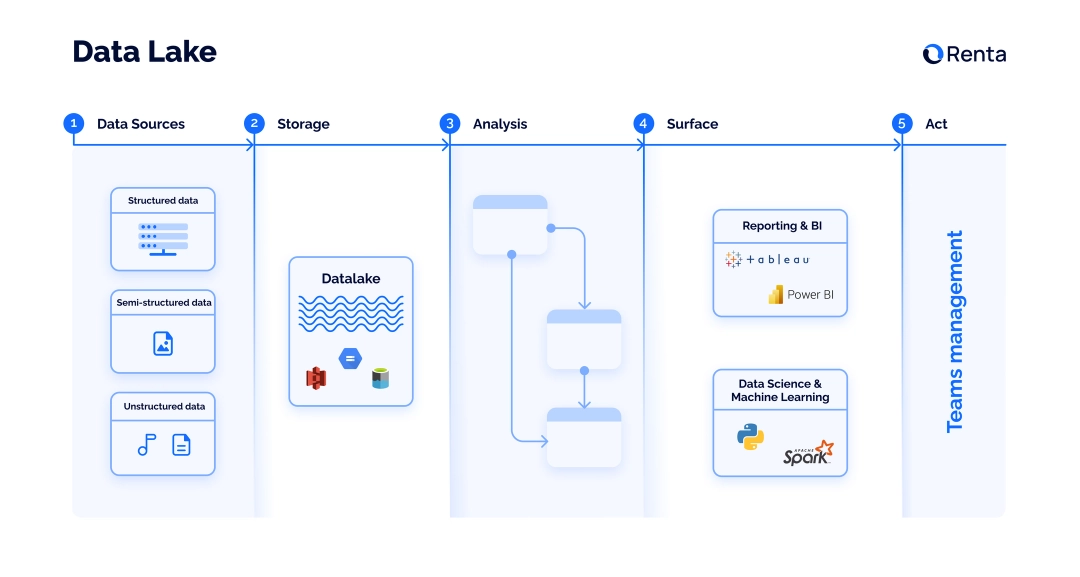
Ingest refers to data transfer through APIs or in batch process. To ingest data, teams use ETL solutions. One of the reliable and easy-to-use ETL tools that allow teams to build pipelines in minutes is Renta’s Marketing ETL, which can be integrated with most of the popular storing solutions.
Storage refers to gathering structured and unstructured data in a centralized repository. The tools commonly used for data storage are Amazon S3, Google Cloud Storage and Azure Data Lake Storage Gen2.
Analyze — on this step, the data is processed and analyzed to find relationships.
Surface implies formatting the insights in perceivable charts, graphs and diagrams with the BI tools.
Act refers to adjusting the business decisions and team management in accordance with the insights found during the previous two steps.
Pros and cons of the Data Lake
Data lakes allow you to store all types of data and quickly dump it for further implementation. However, this structure has some drawbacks.
Pros:
- Data flexibility. Data lakes allow storing data in any format and medium without fitting it into a predefined schema — this means that not a bit of information is lost during the transformation process.
- More opportunities for analytics. Storing the data in an open, raw format allows for more sophisticated analytics and usage of various machine and deep learning algorithms.
- Cost-effective solution. Data lakes are designed to be stored on low-cost commodity hardware, which makes it a lot less expensive per GB than in data warehouses.
Cons:
- Requires strong management. Because the data lake is not organized and the data is not consistent, it can very easily become a data swamp if not properly managed with duplicated and low-quality data.
- Lack of data reliability and security. Implementing proper data security and governance policies is more challenging with data lakes rather than warehouses. For that reason, sensitive data types cannot be completely secure.
Some of the popular cloud-based data lake solutions are Amazon S3, Google Cloud Storage, and Azure Data Lake Storage Gen2. Solutions like AWS feature built-in tools, such as AWS Lake Formation, that allow to make the storage more secure, build a metadata layer and manage access to data within teams.
In general, AWS Lake Formation covers most of the steps of the ISASA pattern.
Data Lake vs. Data Warehouse
So, what's the difference between a data warehouse and a data lake, and when should you use each solution?
Data warehouse architecture allows for collecting and storing structured data. It’s an organized system with a pre-defined schema. This allows for higher data quality and quick and easy access to data. A data warehouse is the best solution for marketing, product, and analytic teams. It doesn’t require a ton of management and provides professionals with ready-to-use data for reports, BI tools and dashboards.
Data lake architecture allows storing all kinds of data, including structured, semi-structured and unstructured. Data doesn’t need to be processed before hitting the data lakes — this means that it can be quickly dumped into the storage and processed later. Solutions like that are useful for advanced analytics, machine learning, and big data analysis. However, without careful management, it can easily become a data swamp with low-quality and duplicated data.
What is a Data Lakehouse?
A data lakehouse is a more recent hybrid solution. A data lakehouse takes the best elements of a data warehouse and combines them with the scalability, flexibility, and low cost of a data lake.
Data lakehouses store both structured and unstructured data in a single repository, allowing for better data governance, easier scalability and lower costs for data storage. Simultaneously, this solution addresses the limitations of both storage formats: the lack of support of advanced data analytics and high scaling costs of data warehouses and complexity of data lakes.
Data lakehouses help companies unlock the full potential of their data by providing access to both real-time and historical data.
Data Lakehouse pattern and components
The data lakehouse pattern is composed of five layers:

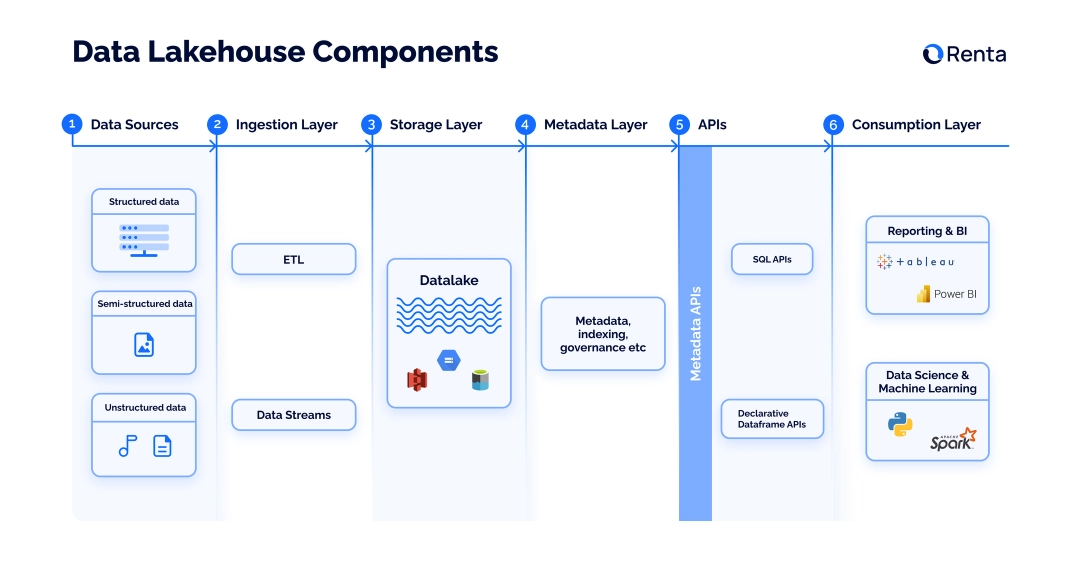
Ingestion layer where data is obtained from various sources and delivered to the database.
Storage layer, a cloud-storage object that accommodates all types of data, including structured, semi-structured, and unstructured data. This component is similar to the data lake storage.
Metadata layer is represented by a unified catalog with structured metadata about all objects in the storage. This layer provides organization to the data lake, enabling simple data management, indexing, schema enforcement, and ACID transactions.
API Layer allows accessing data assets and retrieving them from the storage. APIs allow all end users to pull the data from the storage, process their tasks faster and achieve more advanced analytics. The APIs assist in determining which data items are required for a given application and how to fetch them.
Aside from that, some machine learning libraries, like TensorFlow and Spark, can query the metadata directly and are accessible with open file formats, such as Parquet. Simultaneously, developers can set a structure on and transform data from disparate sources using DataFrame APIs.
Consumption layer includes business tools, applications and workflows that leverage the retrieved data for reporting, BI and AI.
Pros and cons of data lakehouse
Data lakehouses combine both warehouses and lakes and take best from both solutions. However, for some teams, they can still be excrescent.
Pros:
- Support for a wide variety of workloads. Like data lakes, lakehouses can store raw data, which enables advanced analytics and machine learning.
- Data management capabilities. The computing layer of the data lakehouse provides the organization and management features of a data warehouse. This component ensures that the storage will not become a data swamp and will stay structured enough to work efficiently with it.
- Ease of data governance and security. The data lakehouse architecture facilitates the implementation of strong data security and governance mechanisms.
- Cost-effective solution. Data lakehouses utilize low-cost object storage solutions, because data is stored in physical files, such as
JSON. On the other hand, more oftenParquetfiles are used as they are optimized for lakehouses �— this allows for building Data Lake tables and utilizing lakehouse as a data warehouse.
Cons:
- Immature technology. The only downside of the lakehouse pattern is that it is a relatively new approach and it’s still unclear whether it will meet all the expectations. There are years ahead until data lakehouses are as widely-used, well-studied and modified as the older, more mature options.
Data warehouse vs. Data Lakehouse
So, can a data lakehouse replace both data warehouses and lakes? Hardly. It all comes down to the teams that are going to use the data and how they are going to use it.
For business professionals, such as marketers, product managers, or business analysts, a data warehouse is still the best solution — it keeps the data strictly structured and doesn’t overwhelm the teams with unnecessary features and maintenance requirements.
Data lakehouses, on the other hand, are a good solution for companies where data is used by both business professionals and data science teams. This solution will help to keep the data as organized as possible while providing opportunities for advanced analytics.
Data Warehouse vs. Data Lake vs. Data Lakehouse: Overview
There’s no definite answer to which technology is better. It all depends on your business's needs and your teams’ capabilities. Here’s an overview of all three methods.
| Type of solution | Data warehouse | Data lake | Data lakehouse |
|---|---|---|---|
| Data type | Structured data | Structured, semi-structured, unstructured | Structured, semi-structured, unstructured |
| Data quality | Highly curated, reliable data, high level security | Raw data, low quality | Raw and structured data, high quality, high level of security |
| Processing | ETL — extract, load, transform | ELT — extract, transform, load | Both ETL and ELT |
| Pricing policy | Storage is expensive | Storage is cost-effective and easily scalable | Storage is cost-effective and easily scalable |
| ACID-compliance | ACID-compliant | Not ACID-compliant | ACID-compliant |
| Analytics | BI, reporting | Advanced analytics — machine learning, big data analysis | Advanced analytics, BI and other types of analytics workflows |
| Users | BI, reporting and data teams | Data scientists and data engineers | Data scientists and data engineers |
Key takeaways
Data warehouse remains the best option for those who are looking for a solution to collect and keep data that is already structured for quick usage in reports or BI tools. This could apply, for example, to marketing data or customer behavioral data.
Data lakehouses built on platforms like Databricks is a great solution for processing larger — from several terabytes — amounts of structured data. This architecture allows for more cost-effective storage and faster data processing in comparison with data warehouse architecture.
Data lake architecture is a suitable solution for a minimal number of teams who actually know how to manage unstructured data. Otherwise, there’s a very high risk that it will become a data swamp where it’s impossible to find anything.
If you’re currently building your solution for infrastructure for data analytics, use Renta’s solutions for first-party data tracking and Marketing ETL. They allow you to build pipelines in minutes and integrate with popular data warehouses or cloud storage solutions, such as Amazon S3, to create a modern data lakehouse.


