


Incremental models in dbt allow you to process only new or updated rows in a table, significantly improving performance because you don't have to rebuild the entire table from scratch.


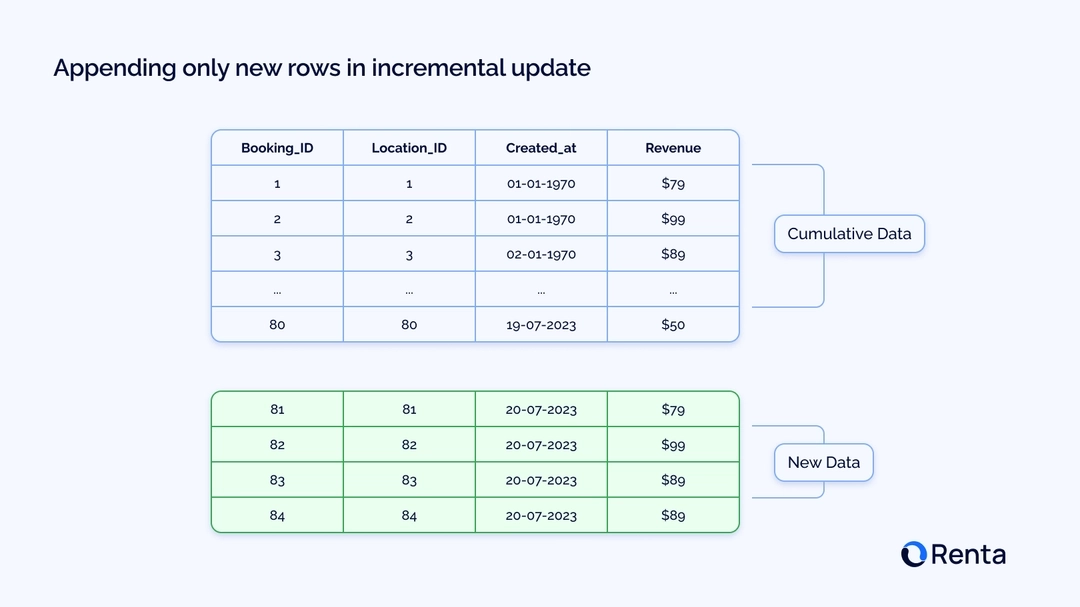
This approach accelerates transformations and reduces computational costs. However, setting up these models can be challenging for beginners.
In this tutorial, we'll cover:
Let’s dive in.
What are Incremental models?
Unlike the traditional table materialization method, which rebuilds the entire table every time you run a job in dbt, incremental models only process new or updated rows in your dataset.

This approach minimizes the amount of data that needs to be transformed, reducing execution time and lowering the cost of running queries.
How does it work?
Incremental models filter rows that have been added or updated based on a specific column. This is typically a timestamp or a unique key (e.g., an order number in integer format). In this context, I will refer to this key as a checkpoint.
The dbt job compares the checkpoint value in that column to the maximum value already present in the destination table.
For example, suppose you're working with a website's behavioural events table. In that case, the incremental model will only process new events with an event datetime greater than the most recent date in your existing data model.
Configuring an incremental model in dbt
The first step when working with incremental models in dbt is to set the configuration model.
Specify the Materialization Type
At the start of the model, you must specify the materialization type as incremental. This is done using the config() block:
{{ config(
materialized='incremental'
) }}This tells dbt that the model should update incrementally, meaning it will add only new or updated rows during each run, rather than overwrite the entire table.
Create a dbt model with an incremental update setup
Next is the main SQL query that will be used to build the model. Here is a sample query from a real project:
{{ config(
materialized='incremental'
) }}
SELECT *, CURRENT_TIMESTAMP() AS batch_timestamp -- capture the time of download
FROM {{ source('tracking_v2', 'renta_events') }}
WHERE date >= '2025-03-01' -- base filter on date
{% if is_incremental() %}
AND dateTime > (SELECT MAX(dateTime) FROM {{ this }}) -- incremental condition
{% endif %}How is_incremental() works
The is_incremental() block is a built-in dbt macro function. It returns true if:
- The table already exists in the database.
- The model is not run with the
--full-refreshflag. - The materialization type is set to incremental.
If all these conditions are met, dbt applies an additional condition to the query:
AND dateTime > (SELECT MAX(dateTime) FROM {{ this }})This condition compares the source table's dateTime column with the destination table's maximum dateTime value.
Run the dbt model
Run the dbt model using the dbt run command:
dbt run --select my_incremental_modelThe model will first check whether the destination table exists and if dbt is running in full update mode.
If the table does not exist, dbt will treat it as a full table creation. If the table exists, dbt will just add new data.
What happens on the first run?
A new table is created. The data is completely reimplemented from the original table into the newly created model.
On subsequent runs, dbt will only add new rows. Tracking new records is most convenient with the added batch_timestamp field, which helps keep track of the data processed in each run. The batch_timestamp is a unique timestamp for each inserted batch. This allows you to keep track of which records were added during each run of the dbt job, which is useful for debugging the model.
Rebuild a model from scratch
Sometimes you may need to completely update a table, such as when you need to add new columns (though there is a better operation for this case).
To perform a full refresh, run the following command:
dbt run --full-refresh --select my_incremental_modelWhat this command does:
- Deletes the current version of the table.
- Creates the table anew.
- Loads all available data from the source table (without the incremental filter).
This command will drop the table, delete all existing data, create a new table with a new schema, and reload data from scratch.
Handling schema changes using incremental strategies
If the schema changes, dbt provides several options for how it should handle this via the on_schema_change configuration:
| Strategy | Description |
|---|---|
| ignore | Default behavior. Changes to the schema are ignored. |
| append_new_columns | Adds new columns to the table, but does not update them with values for existing rows. |
| fail | Stops execution if the schema is not synchronized with the model. |
| sync_all_columns | Adds new columns and removes deprecated columns to maintain synchronization. |
This behavior depends on the data warehouse used (see the dbt documentation for details).
Below is an example of how to set the on_schema_change configuration to your dbt model:
{{ config(
materialized='incremental',
unique_key='eventId',
incremental_strategy='merge',
on_schema_change='append_new_columns'
) }}What's going on here?
Let’s break down the configuration in more detail:
| Parameter | Value | Description |
|---|---|---|
| materialized | incremental | The model will be updated incrementally, only adding new rows. |
| unique_key | eventId | dbt will use eventId as the table's unique key to detect and merge duplicate rows. |
| incremental_strategy | merge | Ensures that new rows are added and existing rows with matching keys are updated. |
| on_schema_change | append_new_columns | If new columns (e.g. user_agent, payment_method) appear in the source, they will be added automatically to the model without causing errors. |
You should keep in mind that new columns added through on_schema_change will not update existing rows.
If you need to update these rows, you must run a model refresh with the --full-refresh flag.
Let's break down a few examples of merge strategies. These examples will demonstrate various model configurations, highlighting best practices for optimizing your incremental data transformations in dbt.
Merge with unique_key
Using the merge strategy, let’s consider a model where new or updated rows replace the old ones based on order_id.
{{ config(
materialized = 'incremental',
incremental_strategy = 'merge',
unique_key = 'order_id'
) }}
{% if not is_incremental() %}
select cast(1 as int) as order_id, 'Alice' as customer
union all
select cast(2 as int) as order_id, 'Bob' as customer
{% else %}
select cast(2 as int) as order_id, 'Charlie' as customer
union all
select cast(3 as int) as order_id, 'Diana' as customer
{% endif %}Result:
-- After 1st run
> select * from orders_merge order by order_id
+-----------+----------+
| order_id | customer |
+-----------+----------+
| 1 | Alice |
| 2 | Bob |
+-----------+----------+
-- After 2nd run
> select * from orders_merge order by order_id
+-----------+----------+
| order_id | customer |
+-----------+----------+
| 1 | Alice |
| 2 | Charlie |
| 3 | Diana |
+-----------+----------+Using the merge strategy along with a unique key, the row with order_id = 2 was updated (Bob → Charlie), and a new order with order_id = 3 was inserted.
Merge with update columns
In some cases, it's necessary to update only specific fields while leaving others unchanged. For example, we may want to update the amount without modifying the already stored order_date.
{{ config(
materialized = 'incremental',
incremental_strategy = 'merge',
unique_key = 'order_id',
merge_update_columns = ['amount']
) }}
{% if not is_incremental() %}
select cast(1 as int) as order_id, 50.00 as amount, '2024-01-01' as order_date
union all
select cast(2 as int) as order_id, 70.00 as amount, '2024-01-01' as order_date
{% else %}
select cast(2 as int) as order_id, 75.00 as amount, '2024-01-05' as order_date
union all
select cast(3 as int) as order_id, 60.00 as amount, '2024-01-03' as order_date
{% endif %}Result:
-- After 1st run
> select * from orders_merge_update_columns order by order_id
+-----------+--------+-------------+
| order_id | amount | order_date |
+-----------+--------+-------------+
| 1 | 50.00 | 2024-01-01 |
| 2 | 70.00 | 2024-01-01 |
+-----------+--------+-------------+
-- After 2nd run
-- For order_id = 2, only the amount was updated. Order_date remained unchanged.
> select * from orders_merge_update_columns order by order_id
+-----------+--------+-------------+
| order_id | amount | order_date |
+-----------+--------+-------------+
| 1 | 50.00 | 2024-01-01 |
| 2 | 75.00 | 2024-01-01 |
| 3 | 60.00 | 2024-01-03 |
+-----------+--------+-------------+The merge_update_columns configuration allows for fine-grained control over which fields are updated. In our example, we retained the original order_date and updated only the amount values.
Conclusion
I hope this material serves as a great starting point for exploring incremental updates in dbt. I also recommend checking out the resources below, which cover different incremental update configuration strategies:
- How to Build Incremental Models by Kahan Data Solutions (I believe this is the best guide you can find on YouTube).
If you have any questions, feel free to contact me on LinkedIn. If you're using dbt, consider integrating Renta ELT with dbt Cloud, which enhances control over the ingestion and management of your data pipelines.




